DSPy for Robust Enterprise AI Applications

If you’ve been building with large language models, you know how fragile prompt-based systems can feel. They work, until they don’t, and then you’re stuck tweaking words like you’re composing a spell. Kevin Madura’s talk on DSPy flips that script, showing how to *program with LLMs* instead of endlessly prompt engineering.
At the core, DSPy gives you clear building blocks: **Signatures** (typed interfaces for inputs and outputs), **Modules** (reusable logic), **Adapters** (control the prompt format, like JSON vs BAML), and **Optimizers** (the real game changer). I’ve spent afternoons chasing prompt regressions, so hearing about optimizers such as MIPRO felt like relief, because they let you automatically tune implementations across models and tasks.
The presentation walks through practical examples you can use. There’s a neat “poor man’s RAG” for attaching documents, a demonstration of how BAML adapters save tokens, and even a PDF boundary detection use case that leans on visual layout cues. You also get a hands-on code walkthrough for mixing models, building datasets, and creating metrics so optimizers actually learn what matters.
What I liked most was the focus on testability and transferability. Treating prompts as internal details makes it easier to version, test, and share modules. That’s where the DSPy Hub idea comes in, a place to exchange proven modules so teams don’t reinvent the wheel.
If you’re curious to dive deeper, watch the full talk here: https://youtu.be/-cKUW6n8hBU
This feels like a practical next step for enterprise AI. Move from brittle tweaks to robust, testable pipelines, and you’ll find your models behave more predictably, scale better, and become easier to maintain. The future looks collaborative and modular, and honestly, I can’t wait to try these patterns in my next project.
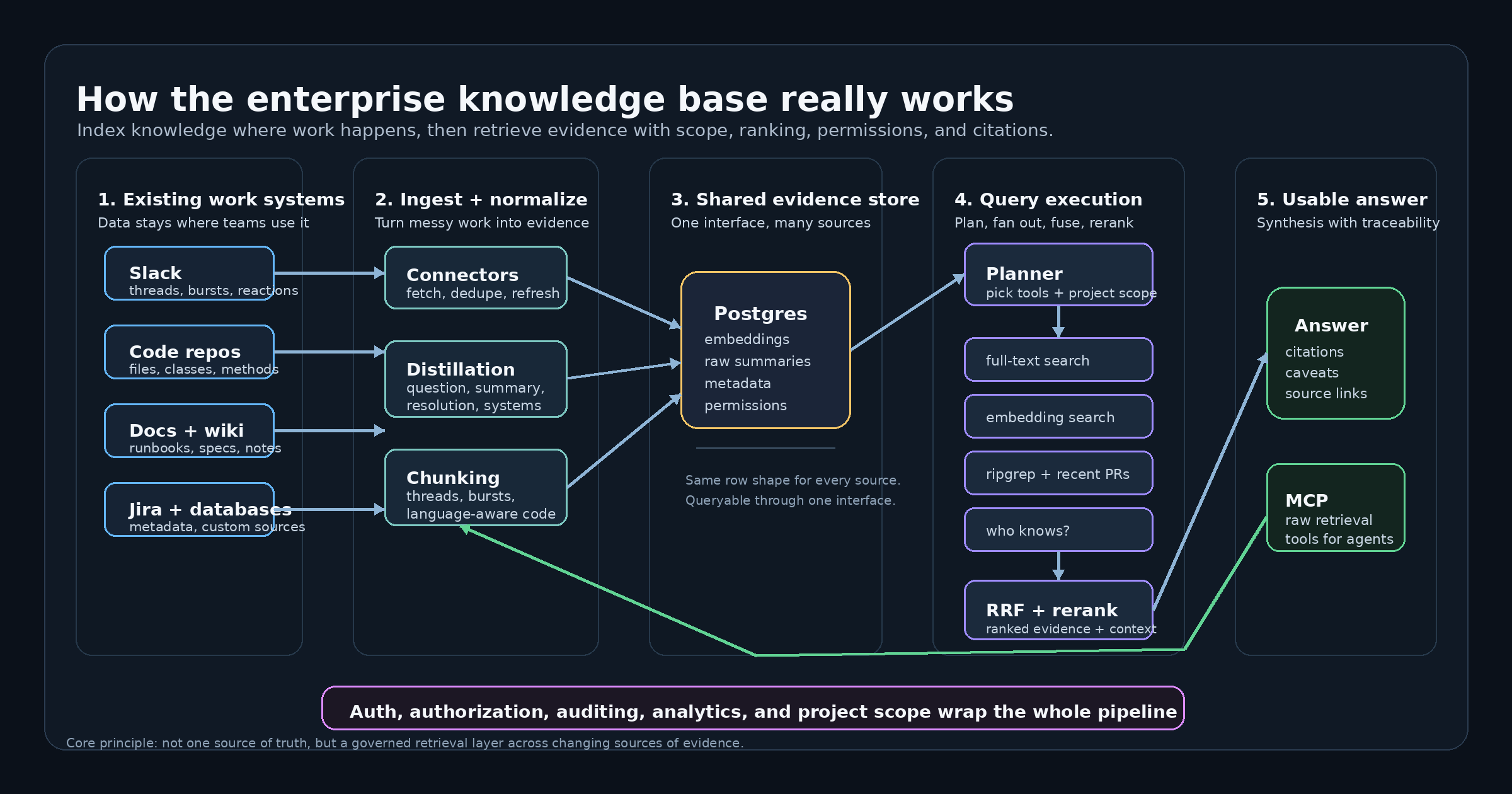
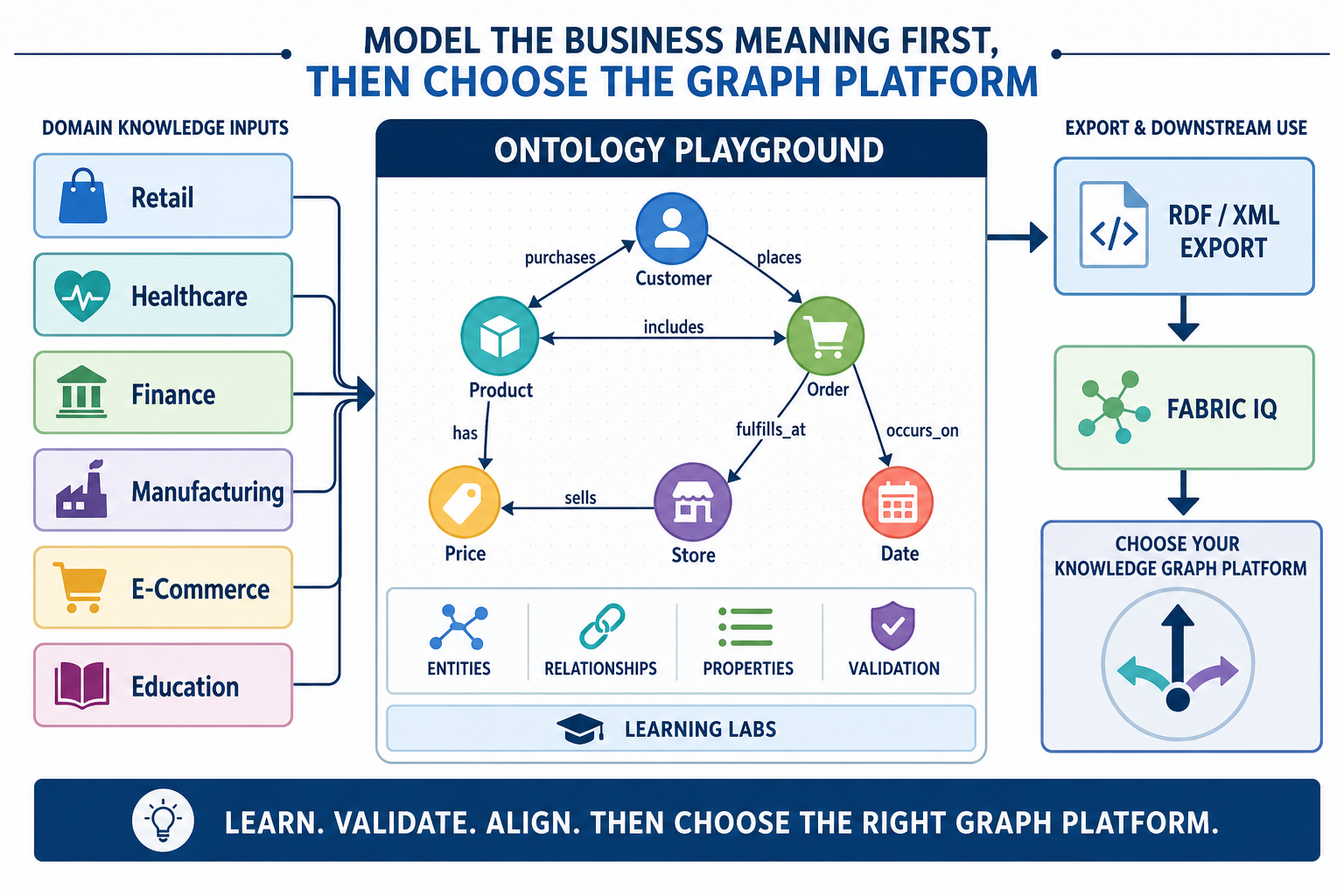




Kommentar abschicken